Benchmarking OSM parsing tools#
TL;DR
Benchmarks show that as of June 2026 pyrosm is the fastest and most memory efficient OSM data parser designed for Python that can extract data efficiently from large PBF files to GeoDataFrames (up to multiple Gigabytes with 24 GiB of RAM). Pyrosm is also able to efficiently crop and modify large .osm.pbf files and save them to disk in PBF format - although it is not the fastest tool around (where C++ based osmium-tool dominates).
Pyrosm aims to be an easy-to-use and fast Python tool for parsing OpenStreetMap data from Protocolbuffer Binary Format (PBF) files into geopandas which is the Python’s go-to library for working with spatial data. Pyrosm has been written mainly in Cython (Python with C-like performance) using vectorized and parallelized operations whenever possible which makes it very efficient for parsing OpenStreetMap data. Pyrosm deserializes the protocol buffer messages using Google’s Protobuf library with its fast C upb backend. Google’s Protocol Buffers is a commonly used and efficient method to serialize and compress structured data which is also used by OpenStreetMap contributors to distribute the OSM data in PBF format (Protocolbuffer Binary Format).
To better understand the performance of Pyrosm, here it is compared against other similar tools. There are various tools available for parsing OSM data, such as OSMnx, Osmosis, pyosmium/libosmium, QuackOSM and osmextract (R). The most similar tool to Pyrosm (in terms of functionality) is OSMnx which makes it possible to retrieve OpenStreetMap data easily into GeoDataFrames utilizing OverPass API.
Here, we compare pyrosm against six other widely used OpenStreetMap tools on a set of identical, verifiable tasks:
Tool |
What it is |
Reads a local |
|---|---|---|
Cython OSM→GeoPandas reader (in-memory + out-of-core engines) |
yes |
|
OSM→GeoPandas/NetworkX via the Overpass API |
no (downloads from Overpass) |
|
DuckDB-based OSM→GeoParquet/GeoPandas reader |
yes |
|
Python bindings to libosmium (streaming C++ reader/writer) |
yes |
|
C++ command-line tool (libosmium); filter + export to GeoJSON, read with GeoPandas |
yes |
|
Java command-line tool for manipulating PBF data |
yes |
|
R package: downloads and reads OSM via GDAL into |
yes |
We benchmark three tasks:
Parse buildings into a GeoDataFrame across a ladder of areas (a single neighbourhood up to a whole country), measuring both time and peak memory and comparing pyrosm’s in-memory and out-of-core engines.
Parse the road network (
highway=*ways) similarly into a GeoDataFrame across a ladder of areas (as with buildings), measuring both time and peak memory and comparing pyrosm’s in-memory and out-of-core engines.Crop a large PBF (all of Finland) down to the Helsinki region and write the result back to disk as a new
.osm.pbf.
How the comparison is kept fair#
Same input. For the parsing tasks every local-file tool reads the same PBF; OSMnx queries the Overpass API for the same geographic extent (the bounding box of that PBF).
Same selection. Each tool is given the same OSM tag filter (
building/highway).Same output, compared by geometry type. OSM tools disagree on whether a tag filter should also return tagged nodes (e.g.
highway=bus_stop) or areas. To compare “apples with apples” as best as possible, we normalise every result to the geometry that defines the task — polygons for buildings, lines for roads — and report those counts side by side so you can confirm the tools really did the same work. In terms of parsed tags, we aim to keep the workload comparable, i.e. also OSM tags are parsed alongside with the geometries.Isolated runs, time and memory. Each parse runs in its own subprocess (the
bench_worker.pyscript), and the notebook samples the whole process tree’s peak memory (psutil) as well as wall-clock time, with a per-size timeout; an out-of-memory kill or timeout is recorded rather than crashing the run. The ladder repeats parsing data from different areas multiple times and records a median time and peak memory of those runs as a result. QuackOSM is called withignore_cache=Trueand pyrosm’s out-of-core cache is cleared before each read, so we measure parsing, not a cache hit.Verified cropping. Each cropped PBF is read back and its building count compared, so a “fast” crop that dropped data is caught.
Not every tool can do every task. OSMnx works from the Overpass API and does not read or crop local PBF files, so it does not take part in the cropping task. Osmosis manipulates PBF data and does not build GeoDataFrames, so it does not take part in the parsing tasks. osmextract (an R package) reads OSM layers through GDAL into
sf/GeoPackage rather than writing a cropped.osm.pbf, so it joins the parsing tasks but not the cropping task. Being an R tool, its parsing results are produced by the companionosmextract_benchmark_scaling.ipynb(run with an R kernel via thebench_worker.Rsubprocess worker). pydriosm also reads local.osm.pbffiles (through GDAL), but it has no read-time tag filter —PBFReadParse.read_pbfreturns whole layers that you filter in pandas afterwards — so it cannot do a like-for-likebuilding/highwayextraction and is left out of these parsing benchmarks. osmium-tool (the libosmium command-line program) parses by exporting to GeoJSON and reading it with GeoPandas, so it joins the parsing tasks, and crops withosmium extractfor the cropping task.
Cores differ by tool. These parsing runs use each tool’s natural defaults rather than pinning cores, so the time chart mixes single- and multi-core readers: pyrosm’s in-memory engine and pyosmium are single-threaded, while QuackOSM (DuckDB threads = all cores), osmium-tool (OSMIUM_POOL_THREADS) and pyrosm’s out-of-core engine with
workers="auto"use multiple cores for larger files and a single-core for files under ~70 MB (i.e. Kamppi and Helsinki run on one core). Peak memory is unaffected by core count — read the time chart with this in mind.
Hardware#
The benchmarks are conducted with MacBook Air M5 laptop with 24GB of RAM, 10 cores and SSD-disk running on MacOS Tahoe 26.5.
Data#
Buildings are parsed across a ladder of areas of increasing size:
Kamppi neighbourhood (clipped from the Helsinki extract),
Helsinki Region (~63 MB, BBBike),
New York City (~150 MB, BBBike),
Paris (~238 MB, BBBike),
Finland (~726 MB, Geofabrik), and
Spain (~1456 MB, Geofabrik).
South America (~4027 MB, Geofabrik) –> Only tested with pyrosm + quackosm
The in-memory engine and OSMnx are limited to the smaller areas they can handle (OSMnx serves the Overpass-friendly smaller extents; the in-memory reader is skipped on Spain due to certain out-of-memory error). Cropping uses all of Finland (approx. 700 MB from Geofabrik) as the large input that gets cropped down to the Helsinki region.
Results#
Here, we introduce the key benchmarking results so that you don’t need to read the whole document. Read further to see the exact results and calculations. The results represent median wall-clock times from a single machine, testing a few datasets in different sizes. Thus, the rankings are indicative rather than exact and should be read with caution. Systematic benchmarking under identical conditions is hard: memory usage, thermal throttling, and background OS processes can all influence timings. However, we made every effort to not interfere with the benchmarking processes in any way while they were running (i.e. nothing else was done on the computer during the runs).
The counts confirm the tools mostly did the same work (read further to see the exact results). Building-polygon and road-line counts agree across the local-file tools to within roughly a percent (≈176,000 buildings and ≈297,000 road lines), which is the evidence that each tool parsed the same features. OSMnx is the exception: it returns a directed routing graph from live Overpass data, so its road count (≈1.06 million edges) is not comparable/fair to the raw way counts of the other tools, which is good to keep in mind. However, we found that this was the fastest way to retrieve the network data with osmnx which is the reason why we relied on this approach.
Parsing buildings — time and memory as the area grows#
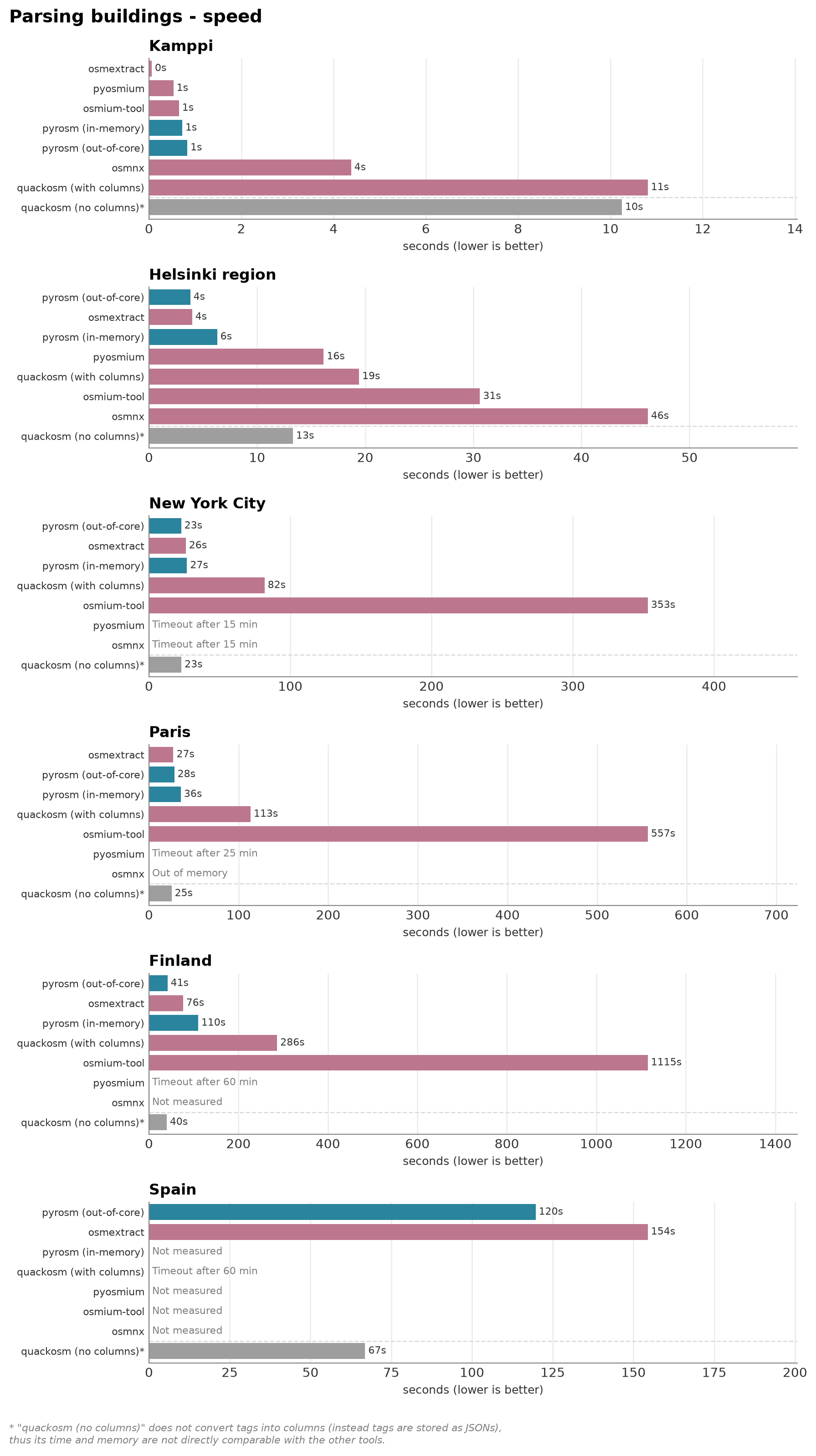
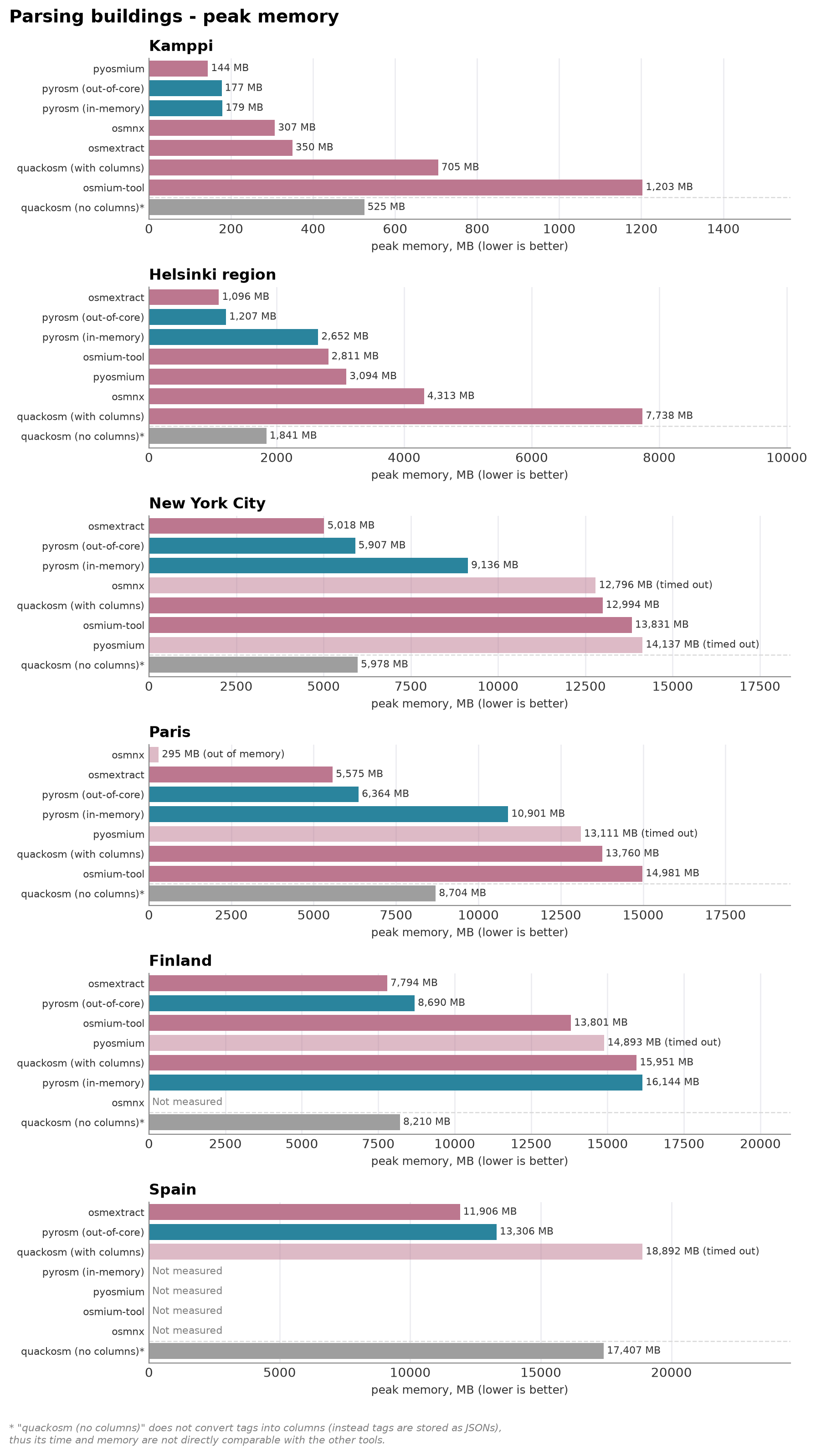
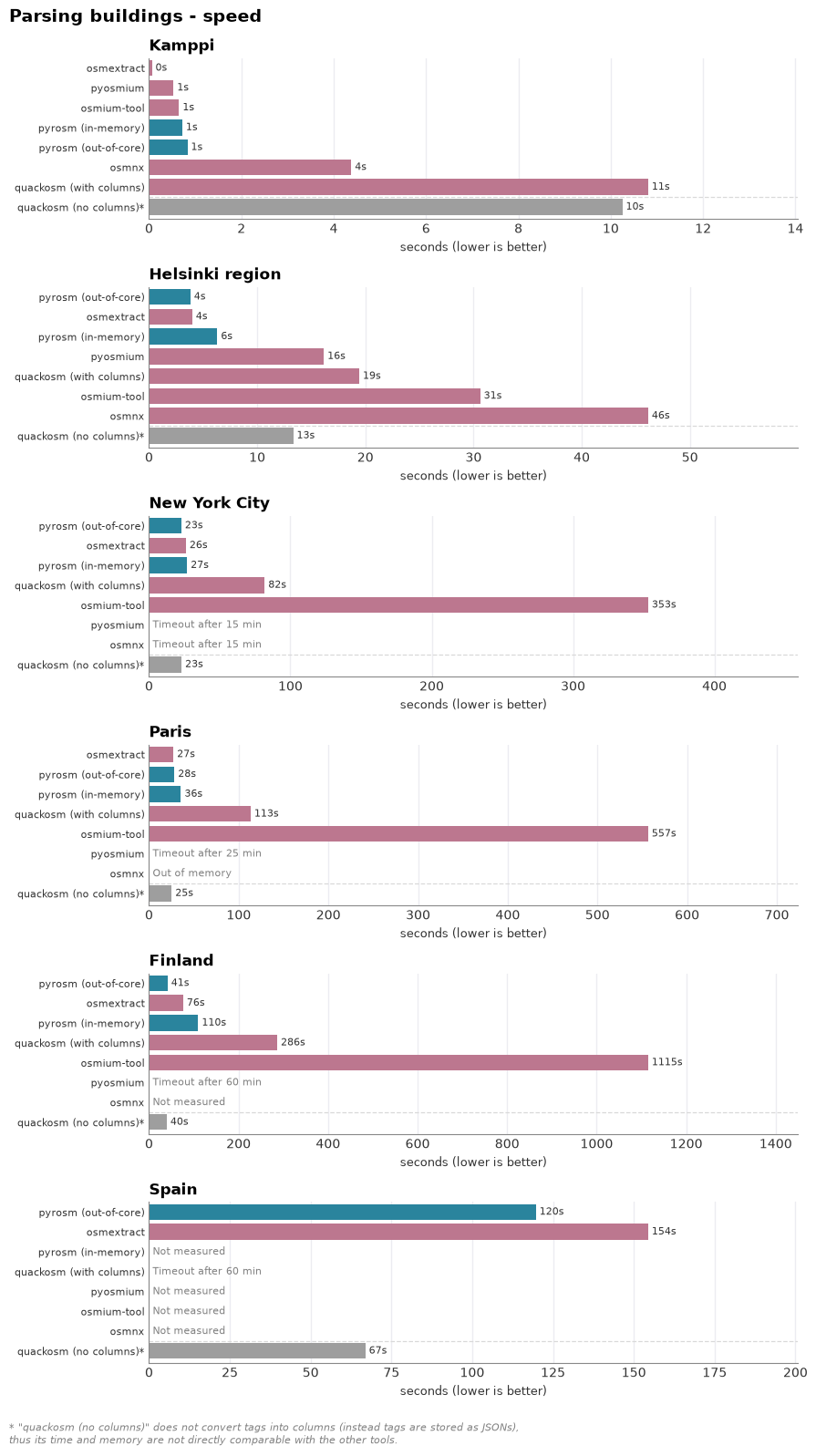
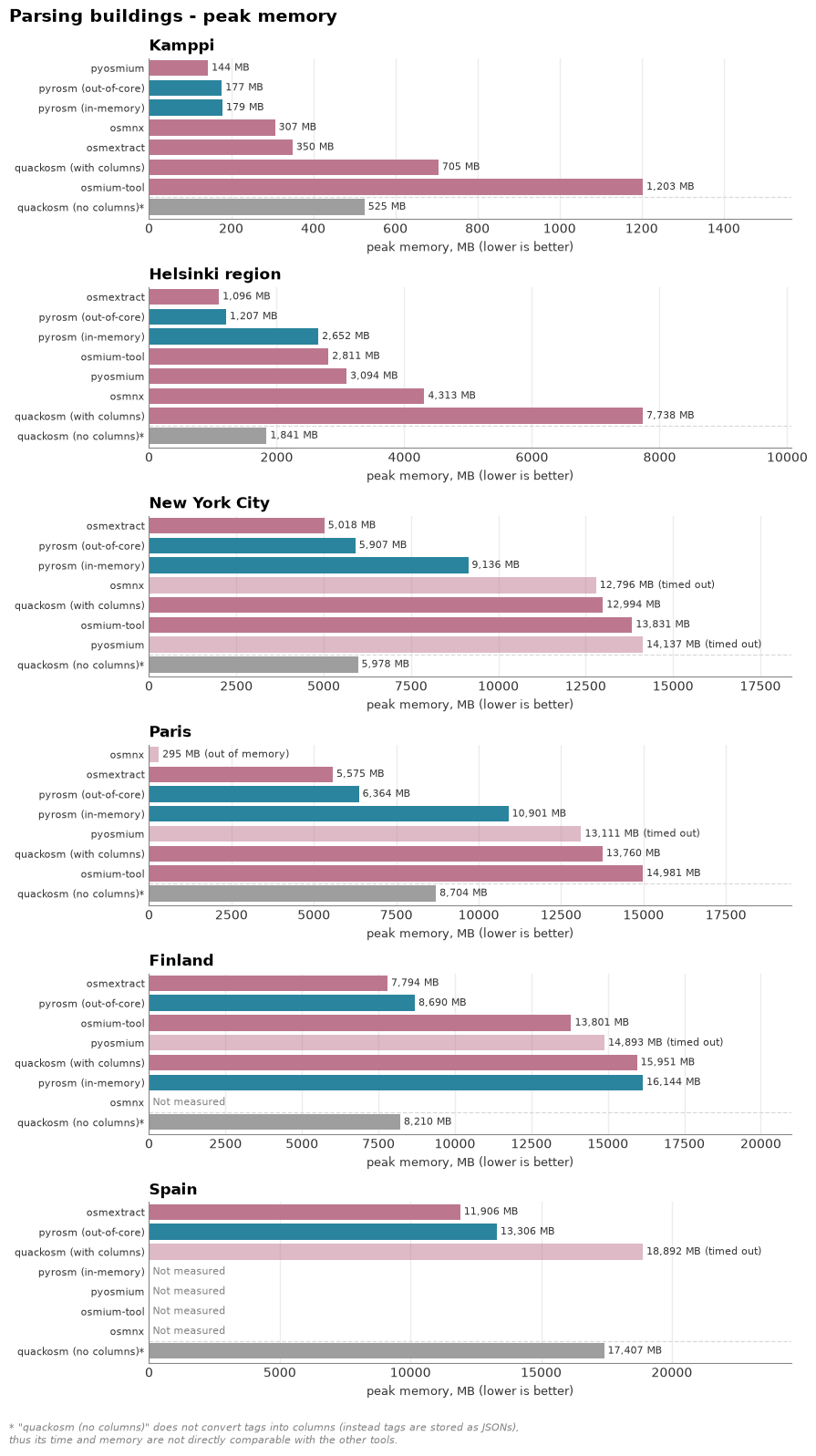
The two charts below plot parse time and peak memory against area size, from the Kamppi neighbourhood up to all of Spain, each parse run in an isolated subprocess. Overall, pyrosm’s new out-of-core backend reader is very performant when reading buildings from OSM.PBF. Together with osmextract (R tool), they represent the fastest parsers in these tests (very close in terms of performance). osmextract (R/GDAL) is timed and memory-profiled on the same files in the companion R notebook. QuackOSM (DuckDB) and pyosmium (streaming) also stay within memory but tend to be slower.
When comparing pyrosm’s two backends, the in-memory engine is quick on the smallest inputs, but its peak memory climbs with size fast. The out-of-core engine (workers="auto") keeps peak memory bounded — on the larger areas roughly half the in-memory peak — and parses Finland and Spain end to end.
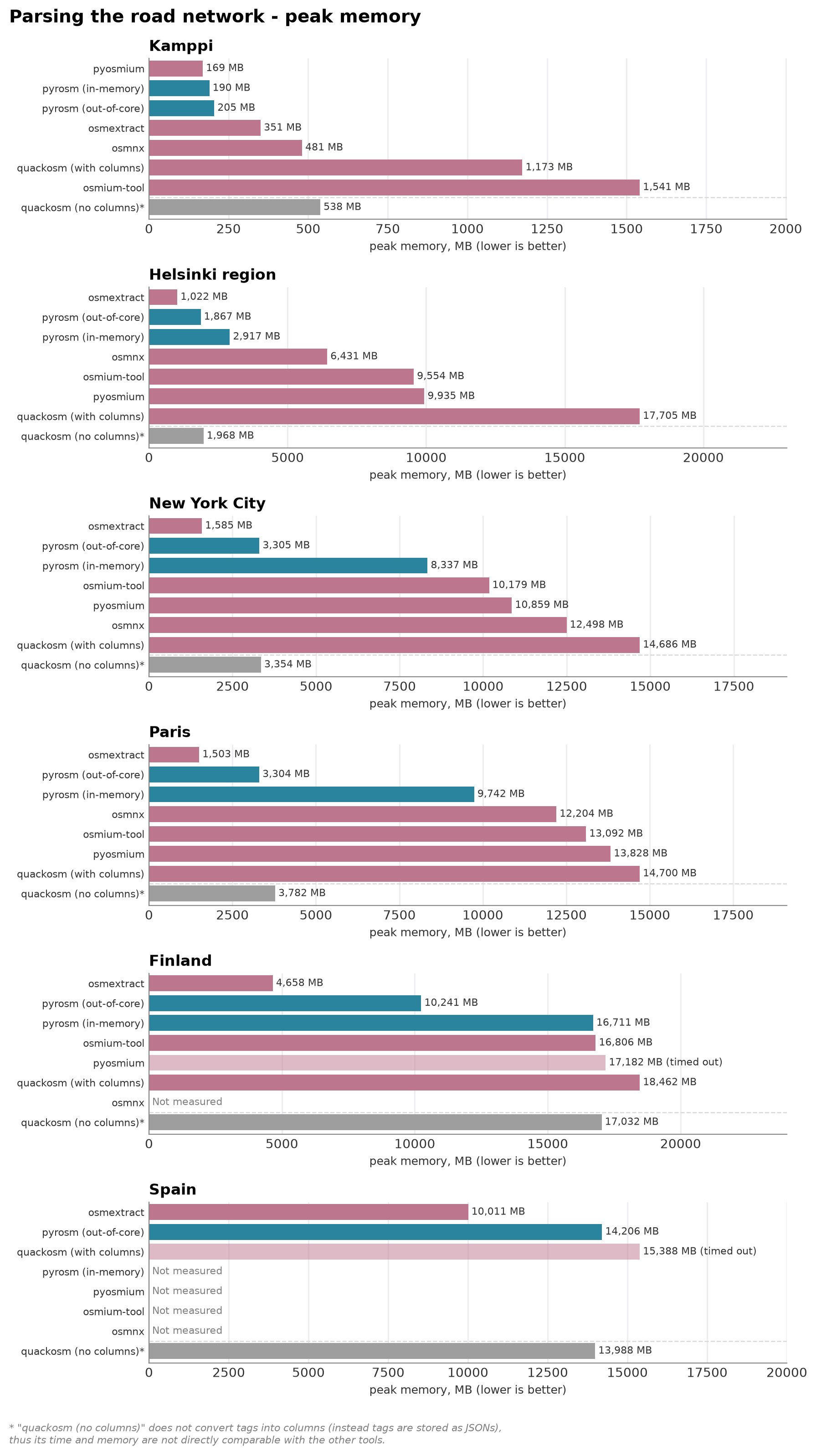
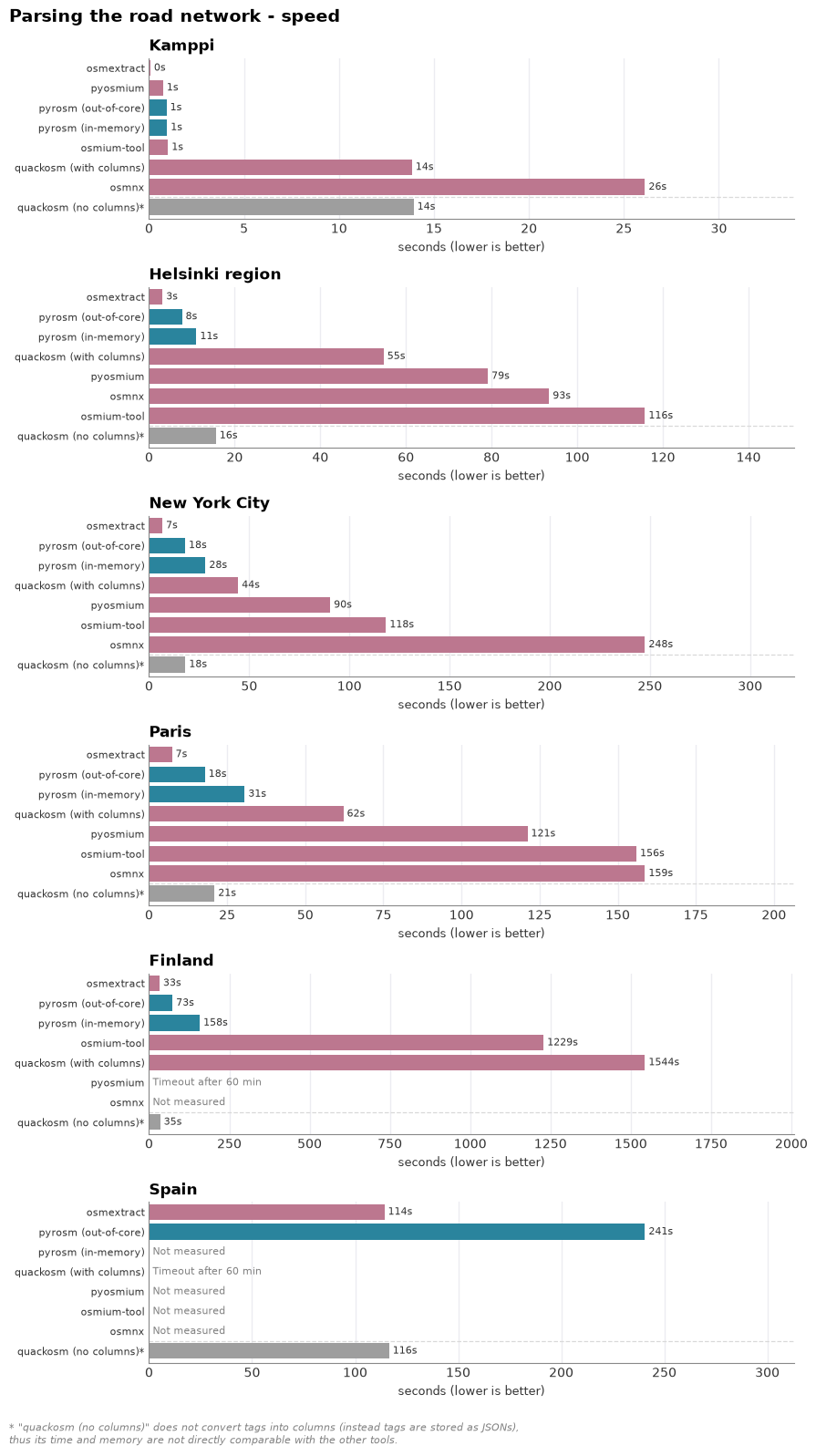
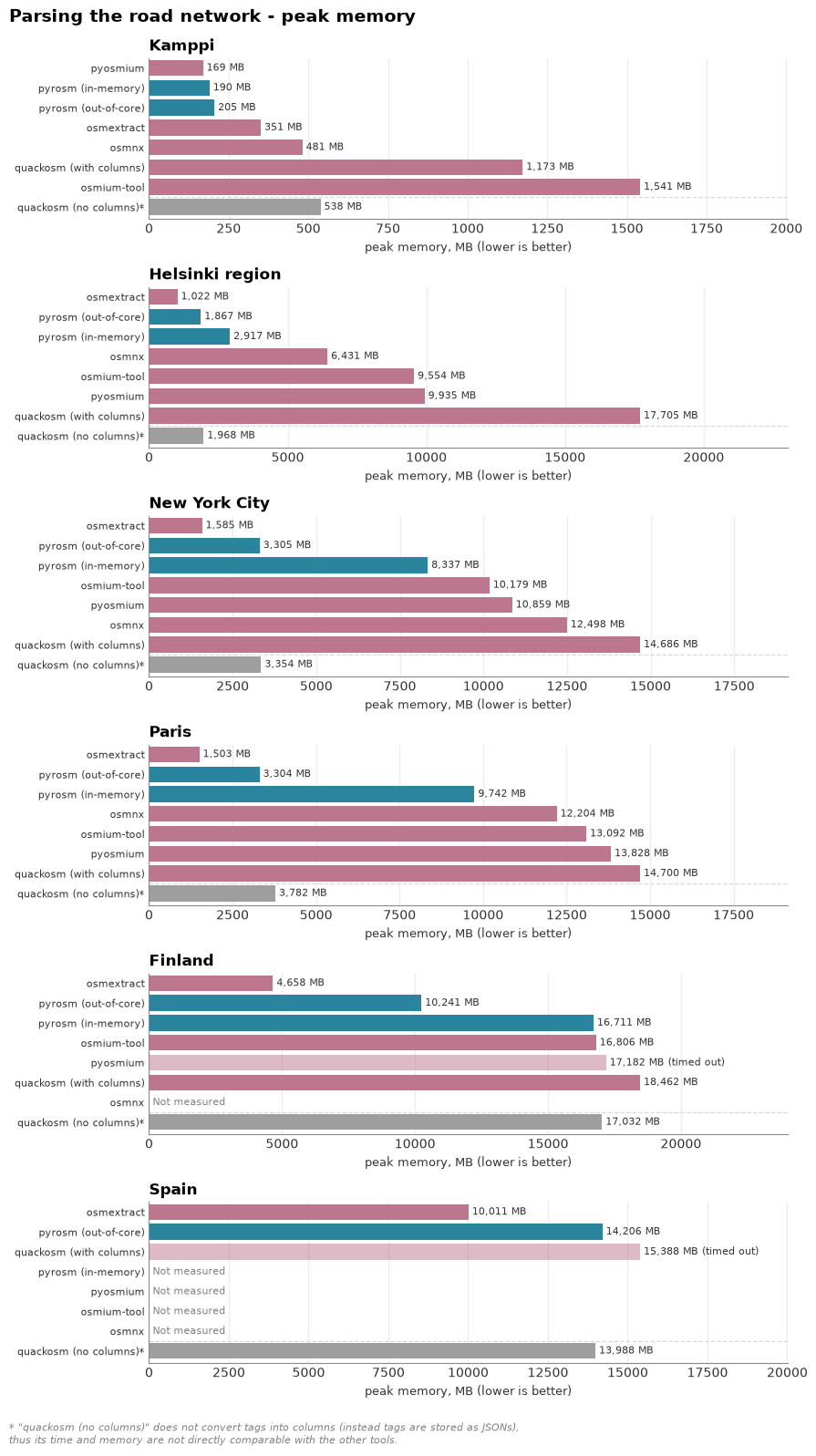
Parsing the road network — time and memory as the area grows#
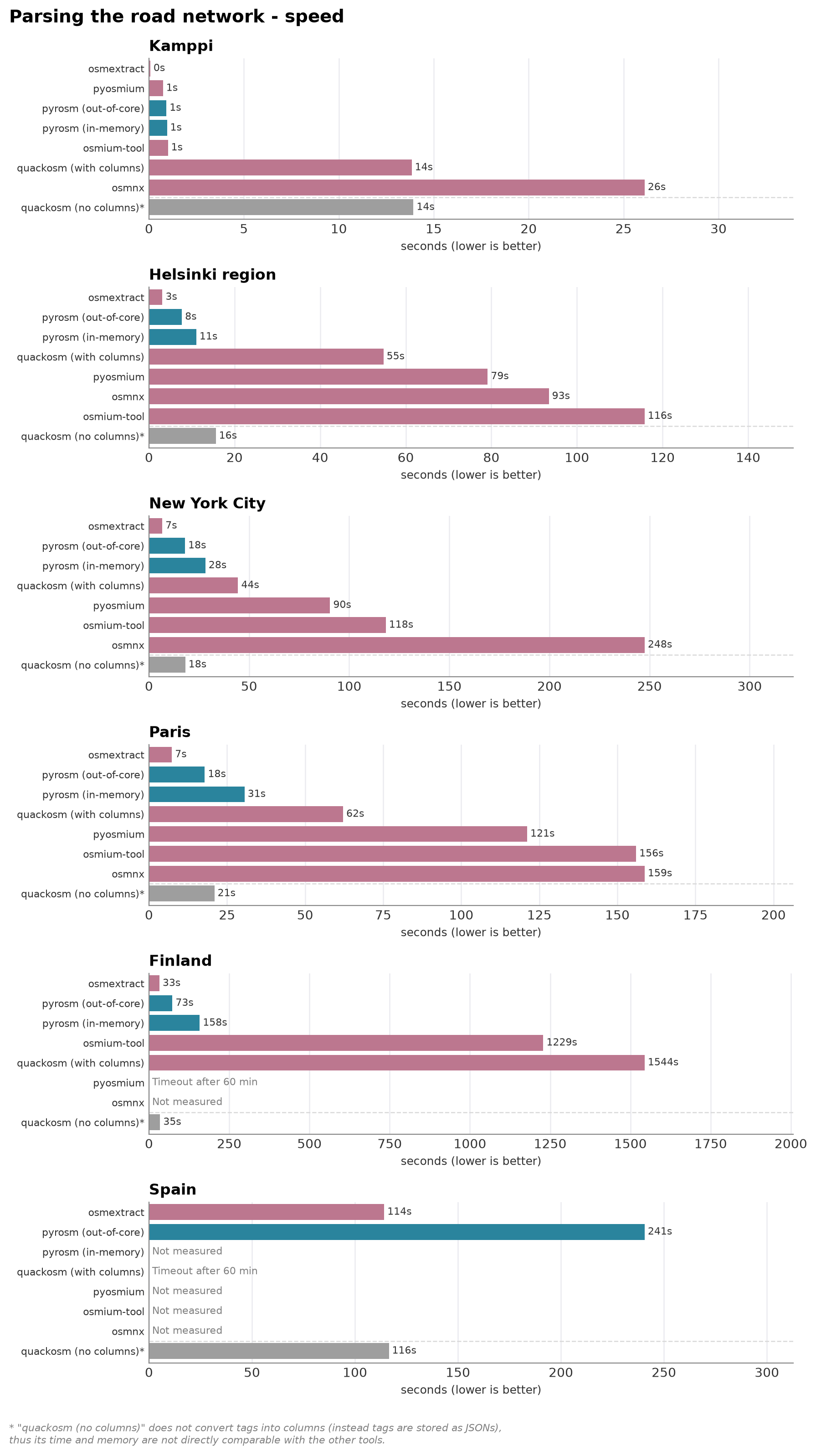
The same comparison as buildings, for highway=* lines. pyrosm’s out-of-core engine again keeps peak memory bounded where the in-memory engine climbs (and is skipped on Spain). Here, the osmextract dominates and is both fastest and most memory efficient parser out of all the tools by a clear margin. pyrosm’s out-of-core engine is the second fastest and memory-efficient tool overall, and most performant one of the Python tools.
osmium-tool’s time is dominated by the GeoJSON export-and-read round-trip rather than the parse, and OSMnx returns a simplified routing graph (higher, non-comparable line count) shown only on the small areas. osmextract (R/GDAL) is the notable performer here — on the network it is faster than pyrosm’s out-of-core engine across the ladder and keeps a low memory footprint.
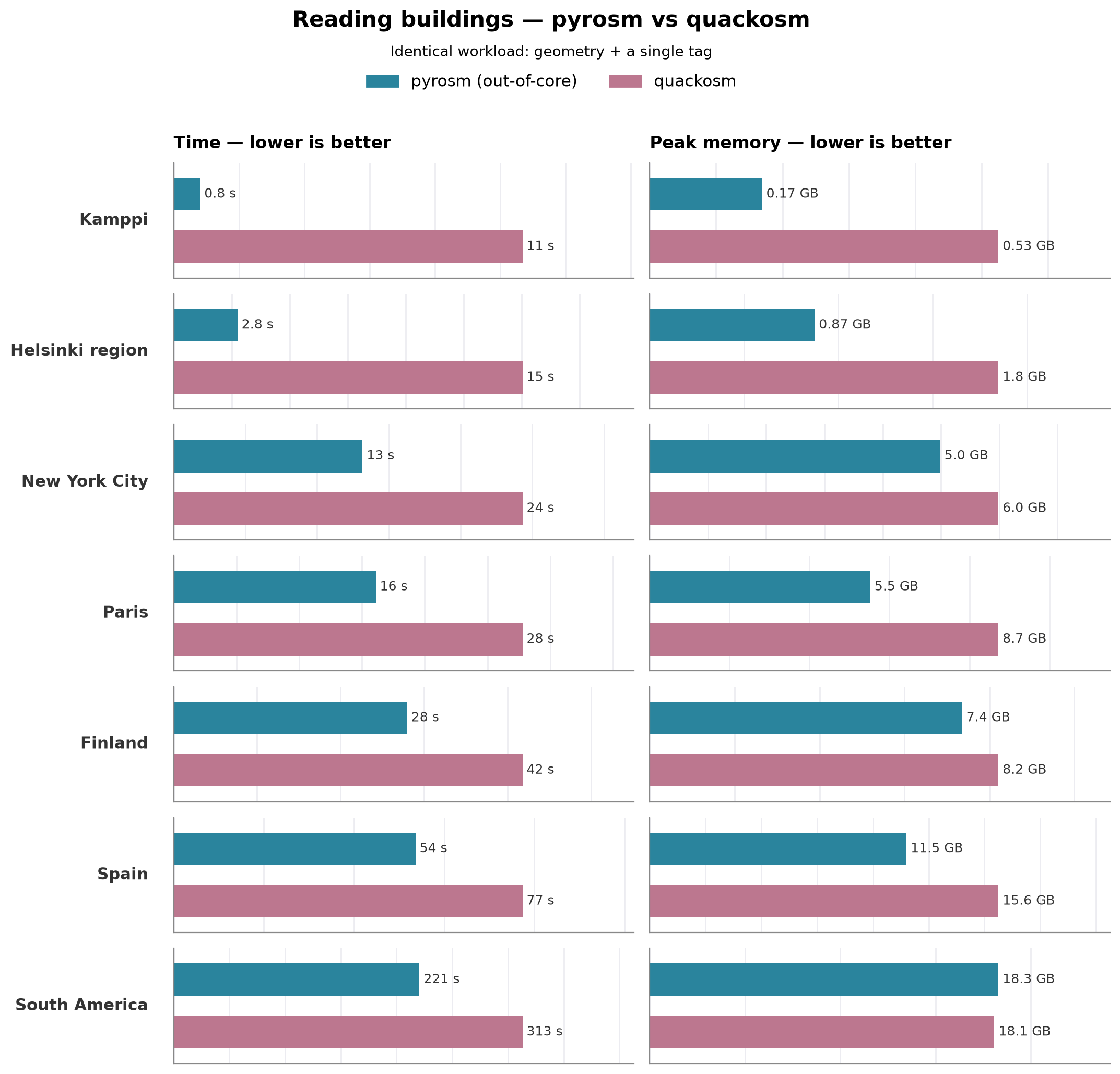
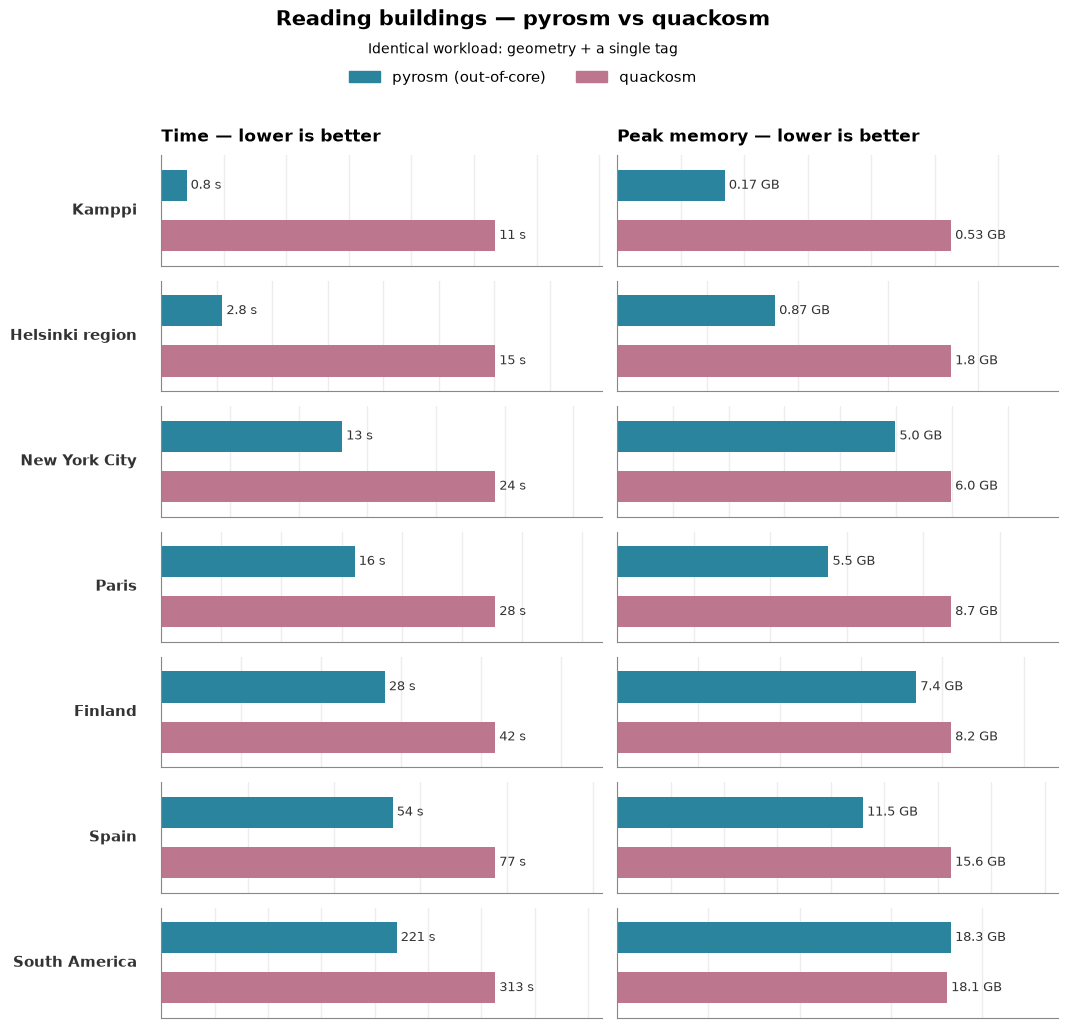
pyrosm vs QuackOSM on a matched workload#
The charts above let each tool follow its own defaults, which do not always do exactly the same tag work — QuackOSM appears twice (with and without tag columns), neither of which lines up exactly against pyrosm. The figure below removes that ambiguity: pyrosm (out-of-core) and QuackOSM both read only the geometry plus the building key — no extra tag columns — across the whole ladder up to South America. On this like-for-like workload pyrosm is faster at every size (e.g. Finland ≈28 s vs ≈42 s, Spain ≈54 s vs ≈77 s, South America ≈221 s vs ≈313 s) and has the lower peak memory at every size except the largest, where the two are essentially tied (South America ≈18.3 GB vs ≈18.1 GB). Both the speed and the memory gap are widest on the small and mid-size areas and narrow as the files grow.
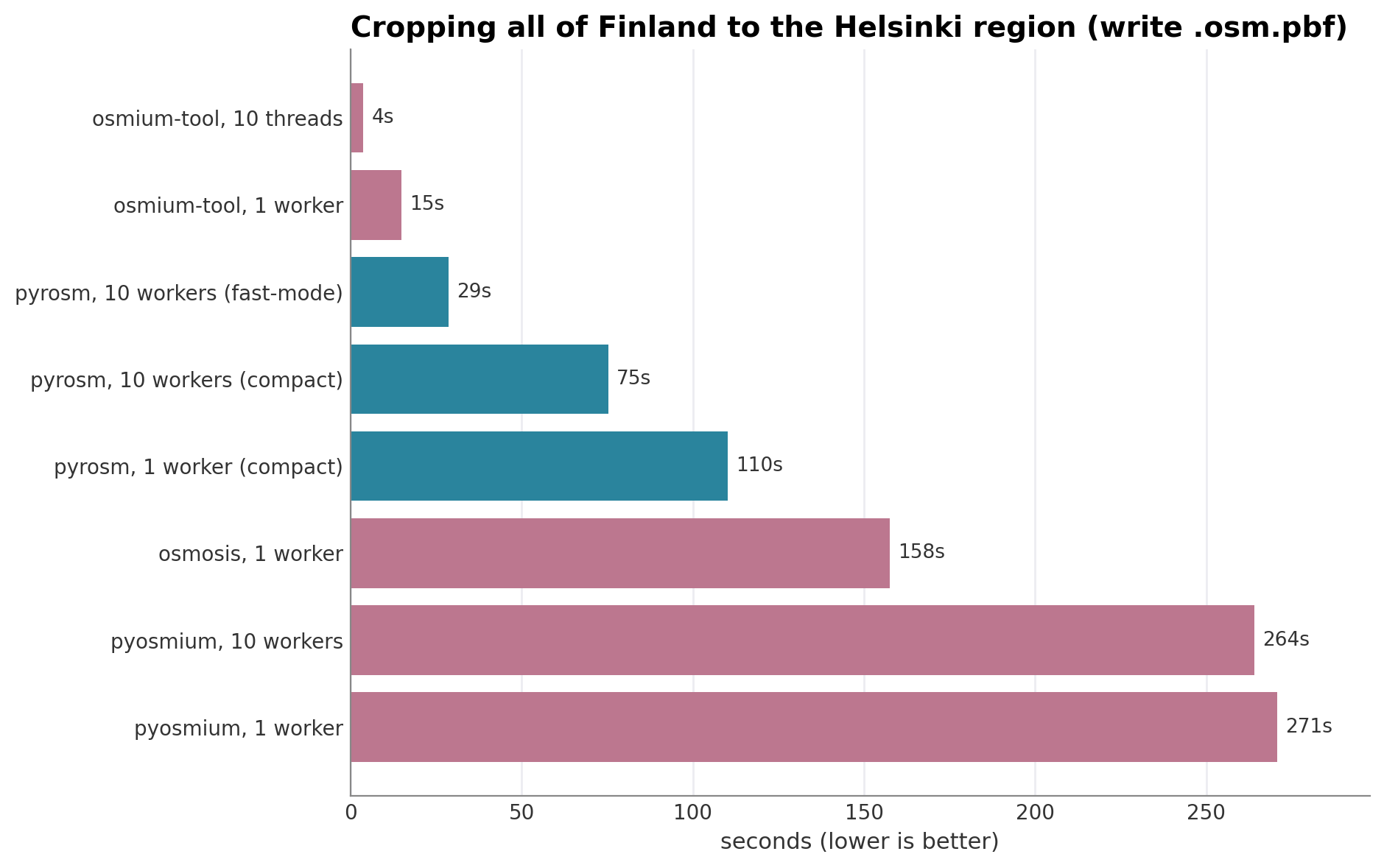
Cropping a country down to a region#
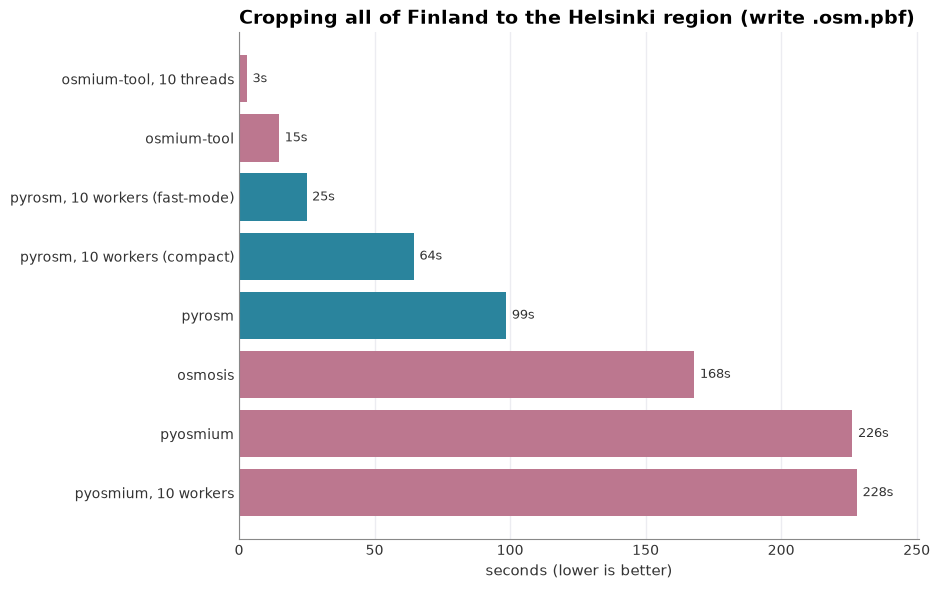
In terms of the third task, focusing on the PBF cropping, osmium-tool is the clear leader, at ≈15 s on a single core and ≈3 s across ten threads, which makes sense as the bounding-box extract is exactly what its C++ engine is built for. pyrosm crops in ≈99 s on one worker and ≈25 s with ten, or ≈64 s in its compact mode that matches osmium-tool’s smaller output file size. Thus, parallelization provides a significant boost to pyrosm cropping capabilities in a similar manner as osmium-tool. Osmosis sits in the middle (≈168 s), and pyosmium is the slowest and does not benefit from more threads (≈226 s to ≈228 s), because its extract loop runs in single-threaded Python.
Where pyrosm fits#
pyrosm is not the single fastest tool at every task: osmextract (R/GDAL) is faster on the road network and very memory-lean, and osmium-tool dominates cropping. On building extraction, though, pyrosm’s out-of-core engine is now at or near the front across the ladder while keeping memory bounded. It is the fastest OSM parser designed for Python, and across the whole set it stays consistently among the quickest. Its main strength is the combination of versatility and ease of use. One OSM object reads buildings, roads, POIs, etc; the same object exports networks to igraph, NetworkX, or Pandarm and crops to a new PBF. Most of these require only a single line of code (e.g. OSM(fp).get_buildings()) returning a fully attributed GeoDataFrame, where pyosmium needs a hand-written WKB loop and osmium-tool needs a two-step shell pipeline plus a file read.
Running the tests#
The rest of this Notebook/page documents how the benchmarks were calculated exactly. With these tests, we have tried to be as fair as possible. However, as we are not the experts of all these tools, there might be ways to make the tools more performant than what they show here. Thus, we would be very happy to hear if any of the benchmarks require improvements to make the comparison between tools fairer. To do this, open an issue in Github.
Installation#
All seven tools (plus the notebook’s plotting/dataframe deps) can be installed into one environment. pyrosm, osmnx, QuackOSM and pyosmium are Python packages; Osmosis is a Java tool; osmextract is an R package.
# Python tools (conda-forge recommended for the geo-stack)
# ipywidgets is needed so QuackOSM/DuckDB can manage their progress bar inside Jupyter.
mamba install -c conda-forge pyrosm osmnx quackosm pyosmium osmium-tool geopandas matplotlib pandas ipywidgets
# Osmosis (Java command-line tool) + a Java runtime
mamba install -c conda-forge openjdk
# then download Osmosis from https://github.com/openstreetmap/osmosis/releases
# and make sure the `osmosis` launcher is on your PATH.
# osmextract is an R package (run via the companion osmextract_benchmark_scaling.ipynb).
# Install R + sf (GDAL) + the Jupyter R kernel from conda-forge, then osmextract from CRAN:
mamba install -c conda-forge r-base r-sf r-irkernel
R -e 'install.packages("osmextract", repos="https://cloud.r-project.org")'
R -e 'IRkernel::installspec()' # registers the "R" Jupyter kernel
If a tool is missing, its cells below are skipped automatically (they are guarded by an availability check), so the rest of the notebook still runs end to end.
Setup: imports, tool detection and helpers#
Many code cells are hidden from the website to make the report easier to read, but you can open the code cells if you’re interested to see how the benchmarks are run.
Detected tools:
pyrosm 0.10.0rc1
osmnx 2.1.0
quackosm 0.18.0
pyosmium 4.3.1
osmosis 0.49.2
osmium-tool 1.19.0
Data#
Buildings and Roads are parsed across a ladder of areas of increasing size, so the timings show how each tool scales with input: Kamppi (a neighbourhood clipped out of the Helsinki extract), the Helsinki Region, New York City, Paris, Finland and Spain. pyrosm is measured with both engines; the in-memory reader and OSMnx run only on the smaller areas they can handle.
Cropping uses all of Finland (a few hundred MB from Geofabrik) as the large input that gets cropped down to the Helsinki region.
Everything is downloaded automatically by pyrosm.get_data(...). The Finland and Spain
downloads are large and may take a while the first time.
Region PBF : /private/var/folders/f2/pgp09jl542zffhtrt2hx8zhh0000gp/T/pyrosm/Helsinki.osm.pbf (62.9 MB)
Finland PBF: /private/var/folders/f2/pgp09jl542zffhtrt2hx8zhh0000gp/T/pyrosm/finland-latest.osm.pbf (725.8 MB)
Buildings area ladder:
Kamppi /var/folders/f2/pgp09jl542zffhtrt2hx8zhh0000gp/T/kamppi.osm.pbf ( 6.1 MB)
Helsinki region /private/var/folders/f2/pgp09jl542zffhtrt2hx8zhh0000gp/T/pyrosm/Helsinki.osm.pbf ( 62.9 MB)
New York City /private/var/folders/f2/pgp09jl542zffhtrt2hx8zhh0000gp/T/pyrosm/newyorkcity.osm.pbf ( 151.6 MB)
Paris /private/var/folders/f2/pgp09jl542zffhtrt2hx8zhh0000gp/T/pyrosm/Paris.osm.pbf ( 238.4 MB)
Finland /private/var/folders/f2/pgp09jl542zffhtrt2hx8zhh0000gp/T/pyrosm/finland-latest.osm.pbf ( 725.8 MB)
Spain /private/var/folders/f2/pgp09jl542zffhtrt2hx8zhh0000gp/T/pyrosm/spain-latest.osm.pbf ( 1456.1 MB)
South America /private/var/folders/f2/pgp09jl542zffhtrt2hx8zhh0000gp/T/pyrosm/south-america-latest.osm.pbf ( 4027.3 MB)
Task 1 — Parse buildings into a GeoDataFrame: time and memory across area sizes#
Every tool reads the same building-filtered features into a GeoDataFrame, repeated across the area ladder (Kamppi → Spain). Following the practice of the osm-python-readers-benchmark, each parse runs in its own subprocess while this notebook samples the whole process tree’s peak memory (psutil) alongside wall-clock time (with a per-size timeout). Also, a crash or out-of-memory kill is recorded. With pyrosm’s out-of-core engine (engine="out_of_core", workers="auto"), it is possible to parse files that no longer fit in RAM as it streams the data into a temporary cache. The cache is cleared before each read, so it runs the full ladder alongside QuackOSM (DuckDB). The in-memory engine (engine="in_memory") is run up to Finland and skipped on Spain, where it is expected to exceed the 24 GB of RAM. pyosmium (the slow but low-memory streaming reader) and osmium-tool (a GeoJSON-export CLI, not a streaming reader) read the local files too: pyosmium is run on the four smaller areas (Kamppi → Paris) and osmium-tool up to Finland. OSMnx is included for the four smaller areas (Kamppi → Paris), but it downloads from the Overpass API rather than reading the local file, so its time and peak memory reflect cloud work and are not directly comparable to the local-file readers.
Each area runs in its own cell below, so you can run and inspect them one at a time; re-running an area’s cell replaces just that area’s results.
# Kamppi (smallest area) - 10 iterations each tool
run_buildings_for_area(AREA["Kamppi"])
Kamppi (6 MB, up to 10x, timeout 120s):
pyrosm (in-memory) 0.72 s 179 MB 665 polys
pyrosm (out-of-core) 0.83 s 177 MB 665 polys
quackosm (with columns) 10.81 s 705 MB 663 polys
quackosm (no columns) 10.25 s 525 MB 663 polys
pyosmium 0.53 s 144 MB 663 polys
osmium-tool 0.65 s 1203 MB 619 polys
osmnx 4.38 s 307 MB 666 polys
# Helsinki region - 10 iterations each tool
run_buildings_for_area(AREA["Helsinki region"])
Helsinki region (63 MB, up to 10x, timeout 300s):
pyrosm (in-memory) 6.31 s 2652 MB 176,900 polys
pyrosm (out-of-core) 3.82 s 1207 MB 176,900 polys
quackosm (with columns) 19.43 s 7738 MB 176,934 polys
quackosm (no columns) 13.32 s 1841 MB 176,934 polys
pyosmium 16.16 s 3094 MB 176,934 polys
osmium-tool 30.61 s 2811 MB 176,440 polys
osmnx 46.14 s 4313 MB 177,382 polys
# New York City - 5 iterations except pyosmium/osmium-tool/osmnx run only once (timeout at 15 minutes)
run_buildings_for_area(AREA["New York City"])
New York City (152 MB, up to 5x, timeout 900s):
pyrosm (in-memory) 26.93 s 9136 MB 1,600,147 polys
pyrosm (out-of-core) 22.83 s 5907 MB 1,600,147 polys
quackosm (with columns) 81.82 s 12994 MB 1,600,196 polys
quackosm (no columns) 22.98 s 5978 MB 1,600,196 polys
pyosmium timeout 14137 MB peak
osmium-tool 353.12 s 13831 MB 1,597,622 polys
osmnx timeout 12796 MB peak
# Paris - pyosmium/osmium-tool/osmnx run only once (timeout at 20 minutes)
run_buildings_for_area(AREA["Paris"])
Paris (238 MB, up to 3x, timeout 1500s):
pyrosm (in-memory) 35.55 s 10901 MB 1,888,219 polys
pyrosm (out-of-core) 28.29 s 6364 MB 1,888,219 polys
quackosm (with columns) 113.32 s 13760 MB 1,888,545 polys
quackosm (no columns) 25.24 s 8704 MB 1,888,545 polys
pyosmium timeout 13111 MB peak
osmium-tool 556.53 s 14981 MB 1,873,213 polys
osmnx OOM/crash (exit 1) 295 MB peak
# Finland (country; in-memory engine might run out of memory)
run_buildings_for_area(AREA["Finland"])
Finland (726 MB, up to 3x, timeout 3600s):
pyrosm (in-memory) 109.89 s 16144 MB 3,146,740 polys
pyrosm (out-of-core) 41.38 s 8690 MB 3,146,740 polys
quackosm (with columns) 286.39 s 15951 MB 3,146,792 polys
quackosm (no columns) 39.55 s 8210 MB 3,146,792 polys
osmium-tool 1115.00 s 13801 MB 3,145,514 polys
# Spain (large country; in-memory engine expected to run out of memory)
run_buildings_for_area(AREA["Spain"])
Spain (1456 MB, up to 3x, timeout 3600s):
pyrosm (out-of-core) 119.69 s 13306 MB 5,554,094 polys
quackosm (with columns) timeout 18892 MB peak
quackosm (no columns) 66.91 s 17407 MB 5,564,483 polys
Task 2 — Parse the road network into a GeoDataFrame: time and memory across area sizes#
The same comparison as buildings, for the road network: every tool extracts highway=* ways as
lines (LineString/MultiLineString) and we record time and peak memory across the area
ladder, each parse in its own isolated subprocess. pyrosm uses get_data_by_custom_criteria({"highway": True}) with both engines. The skips match the buildings task — in-memory pyrosm, osmium-tool and pyosmium are dropped on Spain (likely OOM / timeout), while OSMnx is tested up to Paris extract only. OSMnx returns a simplified routing graph rather than the raw ways, so its line count is higher and not directly comparable —
it is shown as a cloud reference. Each area runs in its own cell below; re-running an area’s cell replaces just that area’s road rows.
# Kamppi (smallest area)
run_network_for_area(AREA["Kamppi"])
Kamppi (6 MB, up to 10x, timeout 120s):
pyrosm (in-memory) 0.95 s 190 MB 4,717 lines
pyrosm (out-of-core) 0.92 s 205 MB 4,717 lines
quackosm (with columns) 13.84 s 1173 MB 4,711 lines
quackosm (no columns) 13.93 s 538 MB 4,711 lines
pyosmium 0.74 s 169 MB 4,771 lines
osmium-tool 1.00 s 1541 MB 4,717 lines
osmnx 26.11 s 481 MB 13,112 lines
# Helsinki region
run_network_for_area(AREA["Helsinki region"])
Helsinki region (63 MB, up to 10x, timeout 300s):
pyrosm (in-memory) 11.07 s 2917 MB 296,962 lines
pyrosm (out-of-core) 7.69 s 1867 MB 296,962 lines
quackosm (with columns) 54.79 s 17705 MB 296,728 lines
quackosm (no columns) 15.62 s 1968 MB 296,728 lines
pyosmium 79.14 s 9935 MB 300,206 lines
osmium-tool 115.82 s 9554 MB 296,962 lines
osmnx 93.43 s 6431 MB 1,059,774 lines
# New York
run_network_for_area(AREA["New York City"])
New York City (152 MB, up to 5x, timeout 900s):
pyrosm (in-memory) 28.19 s 8337 MB 669,058 lines
pyrosm (out-of-core) 18.01 s 3305 MB 669,058 lines
quackosm (with columns) 44.49 s 14686 MB 668,831 lines
quackosm (no columns) 18.16 s 3354 MB 668,831 lines
pyosmium 90.44 s 10859 MB 671,590 lines
osmium-tool 118.28 s 10179 MB 669,058 lines
osmnx 247.54 s 12498 MB 2,346,739 lines
# Paris
run_network_for_area(AREA["Paris"])
Paris (238 MB, up to 3x, timeout 1500s):
pyrosm (in-memory) 30.60 s 9742 MB 620,370 lines
pyrosm (out-of-core) 17.88 s 3304 MB 620,370 lines
quackosm (with columns) 62.17 s 14700 MB 617,765 lines
quackosm (no columns) 20.96 s 3782 MB 617,765 lines
pyosmium 121.11 s 13828 MB 629,737 lines
osmium-tool 156.00 s 13092 MB 620,370 lines
osmnx 158.73 s 12204 MB 1,868,961 lines
# Finland
run_network_for_area(AREA["Finland"])
Finland (726 MB, up to 3x, timeout 3600s):
pyrosm (in-memory) 158.02 s 16711 MB 2,179,186 lines
pyrosm (out-of-core) 73.03 s 10241 MB 2,179,186 lines
quackosm (with columns) 1544.30 s 18462 MB 2,177,377 lines
quackosm (no columns) 34.64 s 17032 MB 2,177,377 lines
pyosmium timeout 17182 MB peak
osmium-tool 1228.56 s 16806 MB 2,179,186 lines
# Spain
run_network_for_area(AREA["Spain"])
Spain (1456 MB, up to 3x, timeout 3600s):
pyrosm (out-of-core) 240.65 s 14206 MB 5,719,679 lines
quackosm (with columns) timeout 15388 MB peak
quackosm (no columns) 116.48 s 13988 MB 5,691,633 lines
Head-to-head: pyrosm vs quackosm, geometry + key only#
The previous comparison was not entirely fair between pyrosm and quackosm, because their workload did not match exactly: quackosm either did too much work (parsed all tags into GeoDataFrame columns, which is expensive) or too little (did not parse any tags into columns). To compare pyrosm and quackosm on equal footing, here, both parse only the geometry and the key tag (building) into a GeoDataFrame — no other tag columns — so neither is doing tag work the other isn’t. pyrosm (out-of-core) uses get_data_by_custom_criteria({"building": True}, tags_as_columns=["building"], keep_other_tags=False) and quackosm uses tags_filter={"building": True}, keep_all_tags=False. The cell below runs this across every area and records the rows under their own task (buildings (geometry + key)).
Head-to-head: geometry + 'building' only (pyrosm out-of-core vs quackosm):
Kamppi (6 MB, up to 10x):
pyrosm (out-of-core) 0.81 s 169 MB 619 polys
quackosm 10.68 s 526 MB 663 polys
Helsinki region (63 MB, up to 10x):
pyrosm (out-of-core) 2.75 s 875 MB 176,440 polys
quackosm 15.04 s 1850 MB 176,934 polys
New York City (152 MB, up to 5x):
pyrosm (out-of-core) 13.17 s 4988 MB 1,597,622 polys
quackosm 24.32 s 5987 MB 1,600,196 polys
Paris (238 MB, up to 3x):
pyrosm (out-of-core) 16.10 s 5522 MB 1,873,213 polys
quackosm 27.79 s 8728 MB 1,888,545 polys
Finland (726 MB, up to 3x):
pyrosm (out-of-core) 27.97 s 7359 MB 3,145,514 polys
quackosm 41.78 s 8215 MB 3,146,792 polys
Spain (1456 MB, up to 3x):
pyrosm (out-of-core) 53.63 s 11509 MB 5,448,594 polys
quackosm 77.37 s 15629 MB 5,564,483 polys
South America (4027 MB, up to 1x):
pyrosm (out-of-core) 226.74 s 16900 MB 23,762,328 polys
quackosm 330.66 s 17967 MB 23,858,068 polys
Test with a large dataset#
The previous test with South America was done only with a single run which does not necessarily produce comparable results. Here, we repeat the parsing tasks running 5 times each:
Head-to-head: geometry + 'building' only (pyrosm out-of-core vs quackosm):
South America (4027 MB, up to 5x):
pyrosm (out-of-core) 220.58 s 18299 MB 23,762,328 polys
quackosm 312.94 s 18083 MB 23,858,068 polys
Task 3 — Crop a large PBF to a region and save to disk#
Crop the Finland PBF down to the Helsinki region bounding box and write a new
.osm.pbf. All four croppers keep complete ways (ways crossing the box keep all their
nodes), so the outputs are directly comparable. Each result is read back and its building
count reported to confirm the crop is a valid subset (the full Finland file has far more).
OSMnx and QuackOSM are not part of this task: OSMnx does not handle local PBF files, and
QuackOSM converts PBF to GeoParquet rather than writing a cropped .osm.pbf.
To keep this a fair per-core comparison, each tool is pinned to a single core here: pyrosm
runs at workers=1 and osmium-tool at OSMIUM_POOL_THREADS=1; pyosmium’s extract loop is
single-threaded Python anyway. Osmosis is the exception — its Java pipeline uses several threads
and can’t be cleanly pinned, so read its time with that caveat. The next section lets every tool
use all cores to show how each one scales.
Task 3 - crop Finland to the Helsinki region (buildings = count read back):
pyrosm 98.6 s 59.6 MB 208,632 buildings
pyosmium 226.3 s 59.6 MB 208,632 buildings
osmium-tool 14.8 s 59.7 MB 208,632 buildings
Jun 26, 2026 8:04:58 AM org.openstreetmap.osmosis.core.Osmosis run
INFO: Osmosis Version 0.49.2
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
Jun 26, 2026 8:04:58 AM org.openstreetmap.osmosis.core.Osmosis run
INFO: Preparing pipeline.
Jun 26, 2026 8:04:58 AM org.openstreetmap.osmosis.core.Osmosis run
INFO: Launching pipeline execution.
Jun 26, 2026 8:04:58 AM org.openstreetmap.osmosis.core.Osmosis run
INFO: Pipeline executing, waiting for completion.
WARNING: A terminally deprecated method in sun.misc.Unsafe has been called
WARNING: sun.misc.Unsafe::arrayBaseOffset has been called by com.google.protobuf.UnsafeUtil$MemoryAccessor (file:/opt/homebrew/Cellar/osmosis/0.49.2/libexec/lib/protobuf-java-3.25.0.jar)
WARNING: Please consider reporting this to the maintainers of class com.google.protobuf.UnsafeUtil$MemoryAccessor
WARNING: sun.misc.Unsafe::arrayBaseOffset will be removed in a future release
Jun 26, 2026 8:07:45 AM org.openstreetmap.osmosis.core.Osmosis run
INFO: Pipeline complete.
Jun 26, 2026 8:07:45 AM org.openstreetmap.osmosis.core.Osmosis run
INFO: Total execution time: 167232 milliseconds.
osmosis 168.0 s 59.2 MB 208,632 buildings
Task 3 with multiprocessing / multithreading — does parallelism speed up the crop?#
Re-run the Finland → Helsinki crop in parallel, using each tool’s own mechanism:
pyrosm parallelises the extract across processes —
to_pbf(..., workers=N); compared here atworkers=1vsworkers=10.pyosmium / libosmium threads the PBF block (de)compression via the
OSMIUM_POOL_THREADSpool, which is on by default (pool ≈ CPU count). It is compared at 1 vs 10 threads; because the kernel’s osmium pool is already initialised by the parsing tasks, the thread count is set in a fresh subprocess (this adds a small fixed start-up). libosmium threads only the (de)compression — the per-element extract loop is single-threaded Python — so the benefits of multithreading is limited via pyosmium (considering slow Python loops).osmium-tool threads its whole C++ extract pipeline via
OSMIUM_POOL_THREADS; because the work is native C++ (not a Python loop), it scales the best of the three. (In the main Task 3 table above it was pinned to a single thread for the per-core comparison.)Osmosis’s
--bounding-boxpipeline has no worker/thread count, so it is left out from this comparison.
Each output is read back and its building count reported, exactly like Task 3, so every parallel crop is verified to keep the same data.
Task 3 in parallel - more workers / threads:
pyrosm, 10 workers (fast-mode) 24.9 s 83.7 MB 208,632 buildings
pyrosm, 10 workers (compact) 64.5 s 59.6 MB 208,632 buildings
pyosmium, 10 workers 228.0 s 59.6 MB 208,632 buildings
osmium-tool, 10 threads 2.9 s 59.7 MB 208,632 buildings
| run | tool | seconds | out_mb | buildings | status | |
|---|---|---|---|---|---|---|
| 0 | pyrosm, 10 workers (fast-mode) | pyrosm | 24.9 | 83.7 | 208632 | ok |
| 1 | pyrosm, 10 workers (compact) | pyrosm | 64.5 | 59.6 | 208632 | ok |
| 2 | pyosmium, 10 workers | pyosmium | 228.0 | 59.6 | 208632 | ok |
| 3 | osmium-tool, 10 threads | osmium-tool | 2.9 | 59.7 | 208632 | ok |
Collect all the Python tool results and visualize#
# Results were exported incrementally as each tool finished (record_result). Load them back here
# for the tables and charts; re-running this cell picks up whatever has been collected so far.
parsing_df = (pd.read_csv(RESULTS_CSV) if os.path.exists(RESULTS_CSV)
else pd.DataFrame(columns=RESULT_COLUMNS))
Results - Tables and Visualizations#
# osmextract is an R package; its results come from the companion notebook
# osmextract_benchmark_scaling.ipynb (R kernel), which writes osmextract_scaling_results.csv
# (buildings and the road network across the area ladder, with time + peak memory) next to this
# file. Load it so osmextract appears in the tables and charts.
osmextract_csv = Path("osmextract_scaling_results.csv")
if osmextract_csv.exists():
rows = pd.read_csv(osmextract_csv)
print(f"Loaded {len(rows)} osmextract row(s) from {osmextract_csv}")
parsing_df = pd.concat([parsing_df, rows], ignore_index=True)
else:
print("osmextract_scaling_results.csv not found - run osmextract_benchmark_scaling.ipynb (R).")
Loaded 12 osmextract row(s) from osmextract_scaling_results.csv
parsing_table = parsing_df
print("Parsing tasks (seconds = median wall-clock; features = normalised count):")
display(parsing_table)
#crop_results = False
if crop_results:
# Combine all results together
all_crop_results = crop_results + parallel_crop_results
crop_table = pd.DataFrame(all_crop_results)
print("\nCropping task:")
display(crop_table)
Parsing tasks (seconds = median wall-clock; features = normalised count):
| task | area | tool | seconds | peak_mb | features | status | |
|---|---|---|---|---|---|---|---|
| 0 | roads | Helsinki region | quackosm | NaN | 0.0 | NaN | OOM/crash (exit 1) |
| 1 | roads | Paris | quackosm | NaN | 0.0 | NaN | OOM/crash (exit 1) |
| 2 | roads | Finland | quackosm | NaN | 0.0 | NaN | OOM/crash (exit 1) |
| 3 | roads | Kamppi | quackosm | NaN | 0.0 | NaN | OOM/crash (exit 1) |
| 4 | buildings | Kamppi | pyrosm (in-memory) | 0.72 | 178.9 | 665.0 | ok |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 99 | buildings | Helsinki region | osmextract | 3.99 | 1095.8 | 176875.0 | ok |
| 100 | buildings | New York City | osmextract | 26.08 | 5018.3 | 1600076.0 | ok |
| 101 | buildings | Paris | osmextract | 27.20 | 5575.1 | 1888259.0 | ok |
| 102 | buildings | Finland | osmextract | 76.19 | 7793.7 | 3146667.0 | ok |
| 103 | buildings | Spain | osmextract | 154.43 | 11905.5 | 5557273.0 | ok |
104 rows × 7 columns
Cropping task:
| tool | seconds | out_mb | buildings | status | run | |
|---|---|---|---|---|---|---|
| 0 | pyrosm | 98.6 | 59.6 | 208632 | ok | NaN |
| 1 | pyosmium | 226.3 | 59.6 | 208632 | ok | NaN |
| 2 | osmium-tool | 14.8 | 59.7 | 208632 | ok | NaN |
| 3 | osmosis | 168.0 | 59.2 | 208632 | ok | NaN |
| 4 | pyrosm | 24.9 | 83.7 | 208632 | ok | pyrosm, 10 workers (fast-mode) |
| 5 | pyrosm | 64.5 | 59.6 | 208632 | ok | pyrosm, 10 workers (compact) |
| 6 | pyosmium | 228.0 | 59.6 | 208632 | ok | pyosmium, 10 workers |
| 7 | osmium-tool | 2.9 | 59.7 | 208632 | ok | osmium-tool, 10 threads |
Area-level visualizations across all tools#
Reading buildings with identical workload — pyrosm vs quackosm#
Time and peak memory side by side, one area per row. Each panel keeps its own scale, so the small areas stay readable next to the big ones — lower is better for both.
Time to crop a country-level PBF into a smaller one#